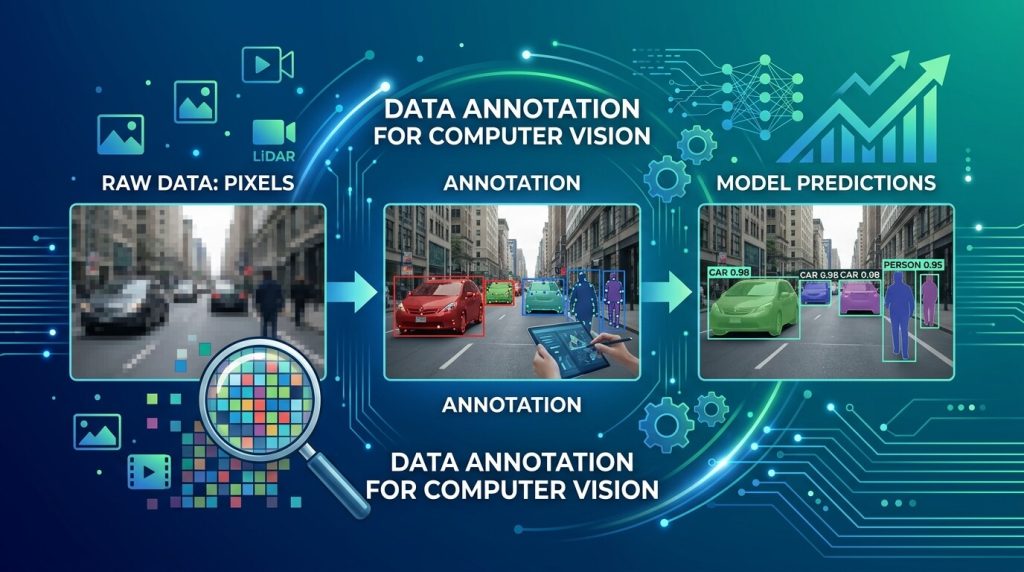
In the digital age, we are surrounded by visual data. Every second, millions of frames are captured by street cameras, medical imaging devices, and smartphone lenses. Yet, for a machine, an image is nothing more than a grid of numbers—a collection of pixels. To transform these raw pixels into actionable predictions, there is a critical, often invisible bridge: Data Annotation.
As we move through 2026, the field of Computer Vision (CV) has transitioned from simple object detection to complex environmental understanding. This leap hasn’t happened solely because of better chips or deeper neural networks; it has happened because of the evolution of high-fidelity data labeling.
At the forefront of this evolution is Synnth AI, providing the infrastructure to turn chaotic visual noise into the structured intelligence that powers our autonomous world.
What is Data Annotation in Computer Vision?
Data annotation is the process of labeling images or videos to train machine learning models. By “tagging” specific features within a dataset, humans (or assisted AI systems) teach the model what to look for.
Think of it as teaching a child to identify shapes. You point to a circle and say “circle” enough times until the child recognizes the pattern. In CV, we do this with bounding boxes, polygons, and keypoints.
The Techniques Driving Modern Predictions
The complexity of the prediction determines the type of annotation required. In 2026, we have moved far beyond simple boxes.
1. 2D & 3D Bounding Boxes
The bread and butter of object detection. Bounding boxes tell a model where an object is. 3D cuboids go a step further, providing depth and orientation—essential for the spatial awareness needed in robotics and self-driving cars.
2. Semantic and Instance Segmentation
While a bounding box is a rough sketch, segmentation is a masterpiece.
- Semantic Segmentation: Every pixel in an image is assigned a class (e.g., “road,” “pedestrian,” “sky”).
- Instance Segmentation: This differentiates between individual objects of the same class (e.g., “Pedestrian A” vs. “Pedestrian B”).
3. Keypoint Annotation
Used primarily for human pose estimation and facial recognition. By marking specific “joints” or facial landmarks, AI can predict movement patterns, detect fatigue in drivers, or even translate sign language in real-time.
4. Optical Flow and Video Tracking
In 2026, we aren’t just looking at static images. Video annotation involves tracking an object across multiple frames. This allows models to predict intent. For example, an autonomous vehicle doesn’t just see a ball; it predicts the ball’s trajectory across the street.
Why Human Intelligence is Still the “Ground Truth”
Despite the rise of automated labeling, the “Human-in-the-Loop” (HITL) model remains the gold standard. AI models can be “lazy”—they often find shortcuts or “hallucinate” patterns that aren’t there.
Human annotators provide the Ground Truth. They understand context, occlusion (when one object hides another), and lighting variations. Synnth AI leverages this by using expert human reviewers to validate synthetic datasets, ensuring that the “pixels” used for training are medically, legally, and logically accurate.
The Role of Synthetic Data: The Synnth AI Advantage
As the demand for labeled data outpaces human capacity, Synnth AI is leading the charge with Synthetic Data Generation.
In scenarios where real-world data is hard to get—such as rare surgical complications or edge-case traffic accidents—synthetic data creates “perfectly labeled” environments. Since the data is generated by a computer, every pixel’s identity is already known. This eliminates the manual labor of labeling while providing a diverse range of training scenarios that real-world photography might never capture.
Industry Impact: Where Predictions are Changing Lives
Autonomous Mobility
The difference between a safe stop and a collision lies in the annotation of “corner cases”—low-light conditions, heavy rain, or a child wearing a dinosaur costume. Detailed segmentation allows these vehicles to navigate the unpredictable nature of human streets.
Healthcare & Diagnostics
From identifying microscopic anomalies in pathology slides to assisting in robotic surgeries, CV models trained on expert-annotated data are achieving accuracy rates that often surpass human diagnostic capabilities.
Precision Agriculture
Drones equipped with CV can identify specific pests or nutrient deficiencies in a single plant among millions. This is made possible by annotators who label thousands of images of healthy vs. diseased crops.
The Future: Self-Supervised Learning and Beyond
As we look toward the end of the decade, the goal is to reduce the “data hunger” of AI. We are moving toward Self-Supervised Learning, where models learn to annotate themselves with minimal human oversight. However, until we reach “General AI,” the quality of the initial “pixels” and the precision of the human-verified “predictions” will remain the most important variables in the equation.